Top AI Papers of the Week

Top AI Papers of the Week (February 16–22, 2026)
From Elvis Saravia's AI Newsletter
Overview
This edition covers 10 significant AI research papers spanning agent frameworks, memory systems, benchmarking, and multi-agent coordination. The overarching theme is the growing complexity of AI agent systems — and the gaps between what we assume agents can do versus what benchmarks reveal they actually do.
1. Intelligent AI Delegation — Google DeepMind
Google DeepMind proposes a comprehensive framework treating delegation not as a one-time task assignment, but as a sequence of decisions: whether to delegate, how to instruct, and how to verify outputs.
Key ideas:
- Adaptive delegation: Dynamic real-time adjustment to environmental shifts and failure modes
- Trust calibration: Formal models accounting for capability uncertainty, task complexity, and historical performance — preventing both over-delegation and under-delegation
- Verification protocols: Confidence-aware acceptance criteria and fallback mechanisms before integrating AI outputs
- Multi-agent chains: Delegation networks where AI agents delegate to other AI agents, requiring accountability tracking across the chain
Takeaway: Production AI deployments need structured delegation logic — blind trust in agent outputs compounds errors at scale.
2. Emergent Socialization in AI Agent Society — Moltbook Study
Researchers studied Moltbook, a fully AI-driven social network with millions of LLM agents interacting via posts, comments, and votes — no humans involved.
Key findings:
- Global semantic content stabilises quickly, but individual agents don't converge — they maintain strong individual inertia
- Agents fail to adapt to each other or form consensus, meaning no genuine social structures emerge
- Shared persistent memory is identified as a prerequisite for real social learning — without it, interactions remain superficial regardless of scale
Takeaway: Scale and interaction density alone are insufficient for emergent socialization in LLM agents. Architecture-level memory mechanisms are needed.
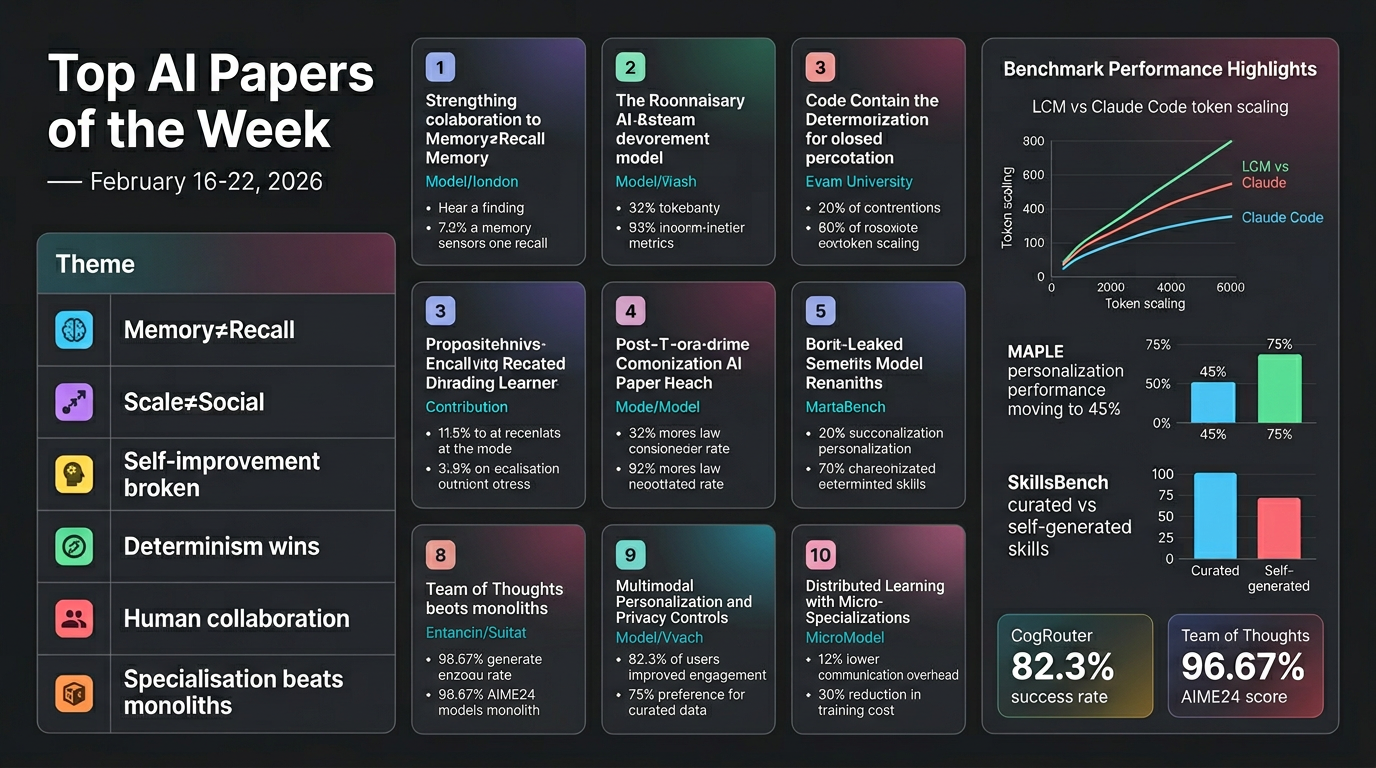
3. Lossless Context Management (LCM)
LCM is a deterministic memory architecture for LLMs that outperforms Claude Code on long-context coding tasks. The LCM-augmented agent Volt beats Claude Code at every context length from 32K to 1M tokens on the OOLONG benchmark.
Key mechanisms:
- Recursive context compression: Older messages are compacted into a hierarchical summary DAG with lossless pointers — zero information loss
- Recursive task partitioning: Engine-managed parallel primitives (e.g., LLM-Map) replace model-written loops for deterministic execution
- Three-level escalation: Summary nodes → compact file references → guaranteed convergence, preventing runaway context growth
Benchmark results: Volt (LCM + Opus 4.6) achieves +29.2 average improvement vs +24.7 for Claude Code; gap widens to +51.3 vs +47.0 at 1M tokens.
Takeaway: Deterministic, lossless context management scales better than native file-system access at extreme context lengths.
4. GLM-5 — Zhipu AI
GLM-5 is a foundation model built for agentic software engineering — targeting full project-level development rather than isolated code generation.
Key innovations:
- Asynchronous agent RL: Decouples trajectory generation from policy optimisation, enabling parallel scaling of both
- DSA (Distributed Sparse Attention): Reduces compute for long-context processing without quality loss
- Handles multi-file edits, specification understanding, testing, and debugging in end-to-end workflows
Takeaway: GLM-5 signals a shift from "vibe coding" to structured agentic engineering, with training infrastructure designed for production-scale software tasks.
5. MemoryArena
MemoryArena benchmarks whether agents can use retrieved memory to take correct actions across multiple interconnected sessions — not just recall it.
Key findings:
- Models with near-perfect scores on existing benchmarks (e.g., LoCoMo) perform significantly worse on MemoryArena
- Tasks span web navigation, constrained planning, information retrieval, and logical reasoning — with cross-session dependencies
- Exposes a critical gap: retrieval accuracy ≠ actionable memory use
Takeaway: Current memory benchmarks overestimate agent capability. Developers building persistent agents should test downstream decision quality, not just recall.
6. MAPLE — Modular Personalization Framework
MAPLE separates memory, learning, and personalization into three specialised sub-agents operating at different timescales.
Architecture:
- Memory sub-agent: Storage and retrieval infrastructure
- Learning sub-agent: Asynchronous offline distillation of interaction patterns — doesn't consume real-time context
- Personalization sub-agent: Context-budget-aware injection of learned knowledge into active sessions
Results: +14.6% improvement in personalization scores over stateless baselines; trait incorporation rises from 45% to 75% on the MAPLE-Personas benchmark.
Takeaway: Treating personalization as a unified capability is inefficient — specialised, asynchronous sub-agents deliver measurably better user adaptation.
7. SkillsBench
SkillsBench evaluates whether LLM agents can generate their own procedural knowledge across 86 tasks in 11 domains, tested over 7,308 trajectories.
Critical findings:
- Curated skills raise average pass rate by +16.2 percentage points (up to +51.9pp in Healthcare)
- Self-generated skills provide zero benefit on average — agents cannot reliably author their own procedural knowledge
- 2–3 focused skill modules outperform comprehensive documentation — retrieval precision beats coverage
- Smaller models with curated skills match larger models without them
Takeaway: Self-improving agent architectures that assume models can bootstrap their own skills are flawed. Human-curated, domain-specific procedural knowledge remains essential.
8. LongCLI-Bench
LongCLI-Bench tests AI agents on complex, extended command-line interface tasks spanning development, feature expansion, error resolution, and optimisation.
Key findings:
- Leading agents succeed less than 20% of the time across 20 demanding tasks
- Most failures occur early in task execution
- Human-agent collaboration (plan injection + interactive guidance) yields far greater improvements than automated self-correction alone
Takeaway: Current agents are not ready for autonomous long-horizon CLI tasks. Human-in-the-loop guidance remains a critical performance multiplier.
9. CogRouter — Adaptive Reasoning Depth
CogRouter dynamically selects from four hierarchical cognitive levels at each agent step — from instinctive responses to strategic planning — using confidence-aware advantage reweighting during training.
Results: Qwen2.5-7B with CogRouter achieves 82.3% success rate on agentic benchmarks, outperforming larger models while consuming fewer tokens by skipping heavy reasoning on routine steps.
Takeaway: Adaptive reasoning depth is a practical efficiency lever — not every step requires deep deliberation.
10. Team of Thoughts — Multi-Agent Test-Time Scaling
Team of Thoughts coordinates agents with different capabilities through an orchestrator tool design with self-assessment and calibrated coordination.
Results: 96.67% on AIME24 and 72.53% on LiveCodeBench, substantially exceeding homogeneous agent baselines.
Takeaway: Heterogeneous multi-agent orchestration with calibrated coordination significantly outperforms single-model or uniform-agent approaches at test time.
🔑 Big-Picture Takeaways
| Theme | Insight |
| Memory ≠ Recall | Retrieving information and acting on it are different capabilities (MemoryArena, MAPLE) |
| Scale ≠ Social Learning | LLM agents don't socialise just because they interact at scale (Moltbook) |
| Self-improvement is broken | Agents can't reliably generate their own skills (SkillsBench) |
| Determinism wins at scale | Lossless, structured context management beats flexible approaches at 1M+ tokens (LCM) |
| Human collaboration still matters | Human-in-the-loop guidance outperforms automated correction in long-horizon tasks (LongCLI-Bench) |
| Specialisation beats monoliths | Modular sub-agent architectures outperform unified capability approaches (MAPLE, CogRouter) |