The jagged frontier was a measurement error — here's what actually smoothed it, why it's accelerating, and 3 prompts to map where your work sits on the new spectrum

Original article: Nate's Substack — Mar 12, 2026
Processed: March 12, 2026
Summary
Main Thesis / Key Argument
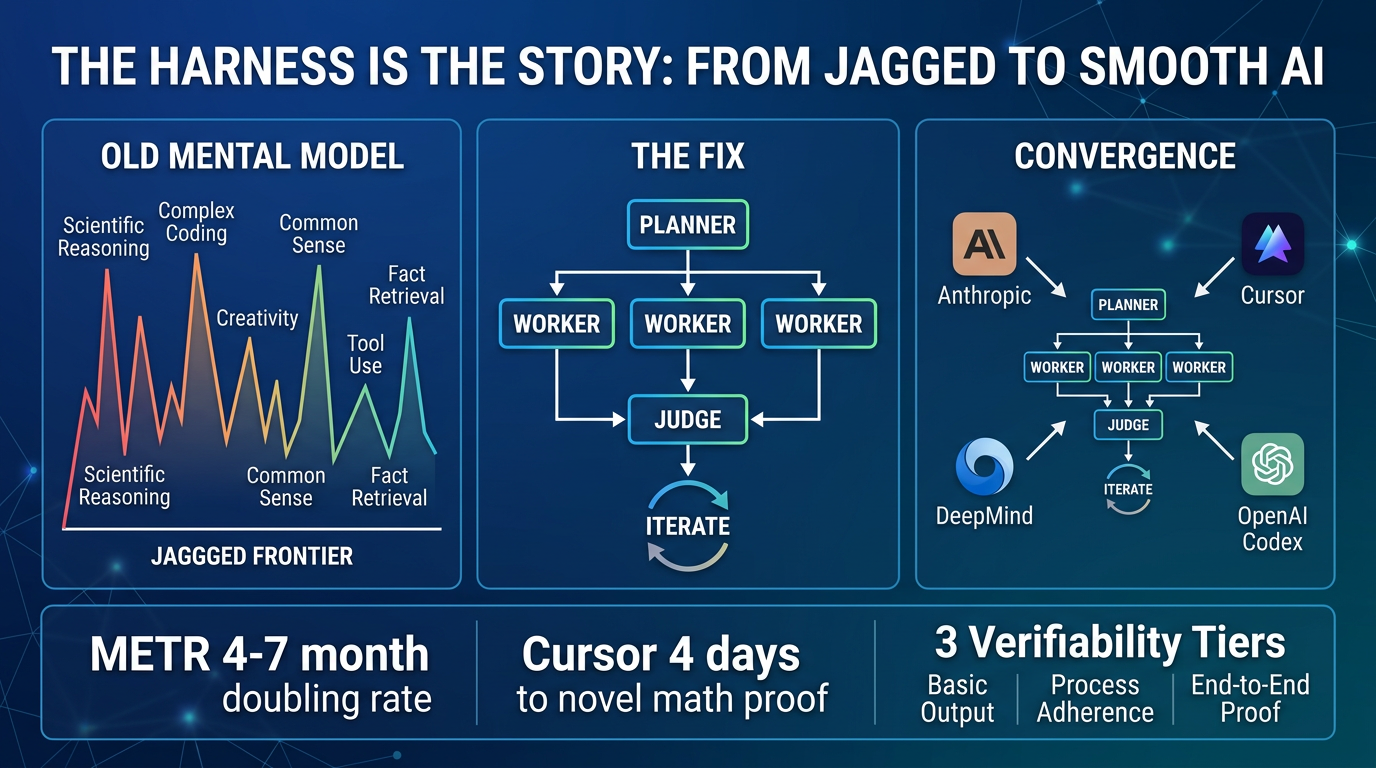
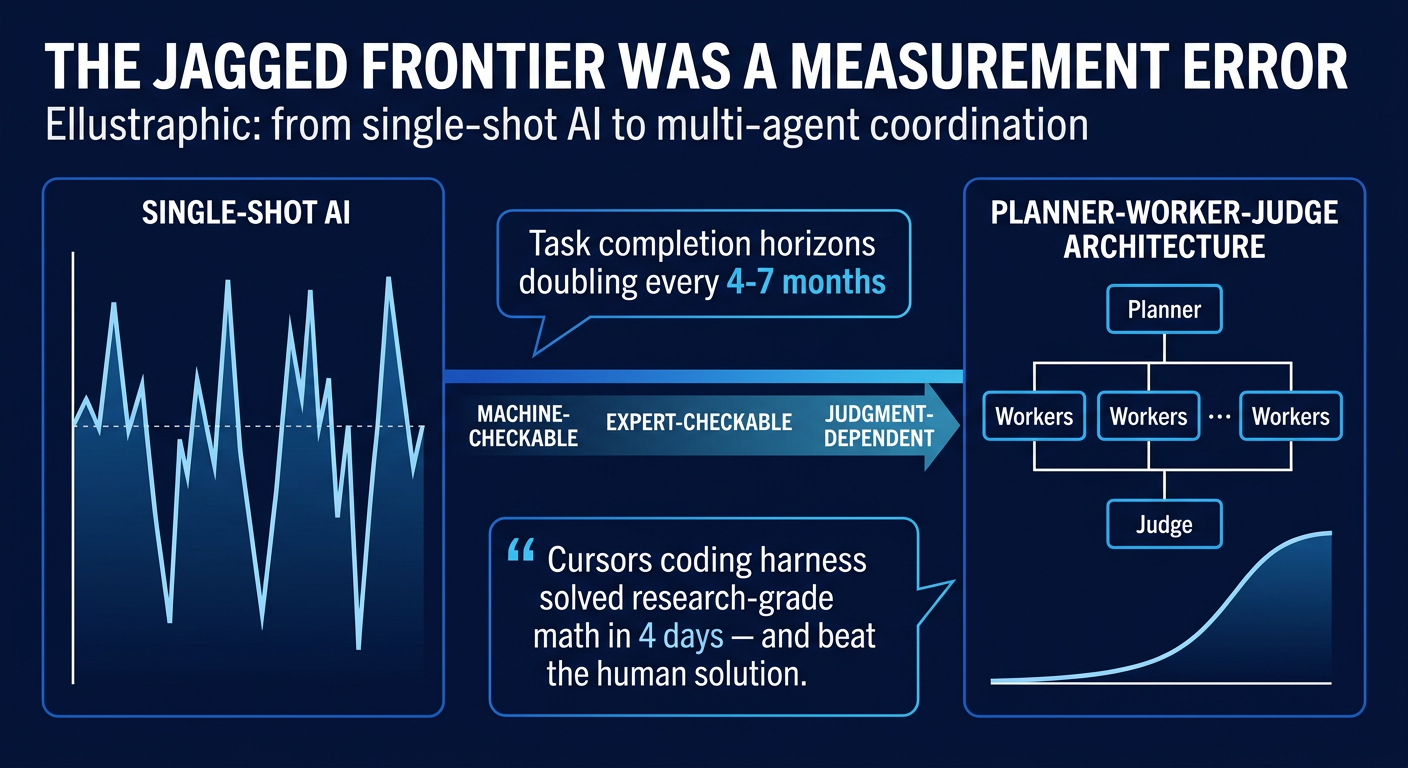
The "jagged frontier" — the widely-adopted idea that AI excels at some tasks and fails unpredictably at others — was never an inherent property of AI intelligence. It was an artifact of single-shot, single-agent interaction: asking AI for one answer in one turn, with no organizational structure, no error-detection, no iterative refinement. When you apply proper coordination architecture (decompose → parallelize → verify → iterate), AI capability smooths dramatically and generalizes far beyond what model improvement alone would predict.
Key Data Points & Findings
- Cursor's breakthrough: A general-purpose coding harness solved First Proof Problem 6 (research-grade spectral graph theory from Stanford/MIT/Berkeley) after running autonomously for 4 days — no human guidance, no domain-specific math machinery. It didn't just solve it; it improved on the human-written solution (better constant: 0.03 → 0.13, full vertex set coverage vs. partial).
- Four organizations independently converged on the same architecture: Anthropic, Google DeepMind (Aletheia), OpenAI Codex, and Cursor — all built Planner-Worker-Judge style multi-agent systems without coordinating with each other.
- METR data: Task completion horizons are doubling every 4–7 months, accelerating to every ~4 months in 2024–2025.
- Cursor's harness scale: Built a web browser in Rust (1M+ lines, ~1 week run), a Solid-to-React migration (266K lines added/193K deleted), a Java language server (550K lines), a Windows 7 emulator (1.2M lines), an Excel clone (1.6M lines).
- Flat coordination failed: When Cursor first tried agents sharing a single file with locks, agents became risk-averse, avoided hard problems, and produced activity without progress. The fix was hierarchy + specialization.
- Model insight: For long-horizon tasks, GPT-5.2 outperforms Claude Opus 4.5 (which stops earlier and takes shortcuts).
Practical Takeaways
- The jaggedness was your architecture, not AI's limitation. Single-shot prompting removes all organizational structure from the work. Multi-agent harnesses restore it.
- The verifiability spectrum is the key framework:
- Tier 1 (Machine-checkable): Code compiles/tests pass/proofs satisfy formal checkers
- Tier 2 (Expert-checkable): Informal proofs, engineering designs, legal briefs — a judge agent can evaluate quality
- Tier 3 (Judgment-dependent): Original theory-building, aesthetic choices, value-dependent strategic decisions
- Most work people assume is Tier 3 is actually Tier 2, and that bucket is getting larger.
- The key career skill shift: From "can do the work" → "can evaluate whether the work is correct." Sniff-checking, domain evaluation meta-skills, and verification competency are gaining value, not losing it.
- Architectural insights transfer at near-zero cost. Cursor didn't build a math harness — they pointed a coding harness at math and ran it for 4 days. The Planner-Worker-Judge insight transfers to science, finance, law, clinical trials.
- Don't wait for a purpose-built domain harness. Organizations that adapt general-purpose harnesses to their work now will move faster than those waiting for specialists.
- Verification is the binding constraint. Harnesses can generate a lot of confident-sounding wrong output. The medium-term solution is better automated verification (Lean formalization, formal proof checkers).
Prompts & Frameworks Included
- Planner-Worker-Judge Architecture: The convergent multi-agent pattern — Planners explore and create tasks, Workers execute in isolation, Judge evaluates and triggers the next cycle. Clean restarts (new agent with fresh context) proved critical.
- The Verifiability Spectrum: A 3-tier framework for classifying your work's harness-readiness.
- "Sniff-checking" concept: The domain evaluation meta-skill that becomes more valuable as execution gets automated.
Prompt Kit
Source: Grab the Prompts
Prompt Kit: The Harness Is the Story
This kit operationalizes the core insight from the article: AI's "jagged frontier" was an artifact of single-shot usage, not a property of AI intelligence. These three prompts help you audit your work for harness-readiness, simulate the Planner-Worker-Judge architecture on a real problem, and map the evaluation meta-skills you need to develop as execution gets automated.
How to use this kit
Prompt 1 is your starting point — run it to understand which parts of your work are ready for structured AI delegation today. Prompt 2 is the engine — use it whenever you face a complex task that would normally get a mediocre single-shot AI response. It forces the decompose-parallelize-verify-iterate pattern that the article identifies as the breakthrough. Prompt 3 is your career strategy — run it once, revisit quarterly.
All three work in any capable AI assistant (ChatGPT, Claude, Gemini). Prompt 2 benefits most from thinking-capable models and long conversations — don't rush it.
Prompt 1: Verifiability Audit — Map Your Work to the Harness Frontier
Job: Decomposes your actual work into sub-tasks and classifies each one on the article's verifiability spectrum (machine-checkable → expert-checkable → judgment-dependent), then produces a prioritized action plan for structured AI delegation.
When to use: When you want to figure out how much of your job is actually harness-ready — and you suspect the answer is "more than I think."
What you'll get: A detailed decomposition of your role into 15-30 sub-tasks, each classified by verifiability tier, with a priority matrix showing what to delegate now, what needs verification infrastructure first, and what remains genuinely human.
What the AI will ask you: Your role/title, the 3-5 major work products you produce, how quality is currently evaluated in your work, and what "getting it wrong" looks like in your domain.
Prompt 2: Harness Simulator — Planner-Worker-Judge for Complex Tasks
Job: Takes a complex task you'd normally handle in a single AI prompt (and get mediocre results) and works through it using the Planner-Worker-Judge pattern — decomposing, executing sub-tasks independently, verifying, and iterating — within a single conversation.
When to use: Whenever you have a meaty problem that you know a single-shot prompt won't handle well. Strategy documents, research synthesis, complex analysis, architectural decisions, thorough investigations. This is the prompt that operationalizes "the harness is the story."
What you'll get: A multi-phase output where the AI explicitly decomposes your problem, works each piece separately, evaluates the results critically, and revises — producing substantially better output than a single-shot attempt.
What the AI will ask you: The complex task you want to work through, what "done well" looks like, and your role in verifying the output.
Prompt 3: Evaluation Meta-Skills Map — What to Get Good At Next
Job: Identifies the specific evaluation competencies in your domain that become more valuable as AI handles more execution work — the "sniff-checking" skills the article identifies as the key differentiator.
When to use: For career planning and professional development. Run it when you want to understand what skills to invest in given the shift from execution to evaluation as the locus of professional value.
What you'll get: A concrete map of evaluation skills specific to your field, rated by current importance vs. projected importance, with specific ways to develop each one.
What the AI will ask you: Your field, your current skill set, and where you've seen AI produce "confidently wrong" output in your domain.
Infographics