The Gap of Judgement: The Missing Piece for Enterprise AI Transformation (LLM Watch, Mar 06 2026)

Originally published on LLM Watch by Pascal Biese — March 6, 2026.
Summary
This article makes a compelling case that enterprise AI transformation has stalled not due to capability gaps, but due to a control gap — and lays out a concrete architectural framework for bridging it.
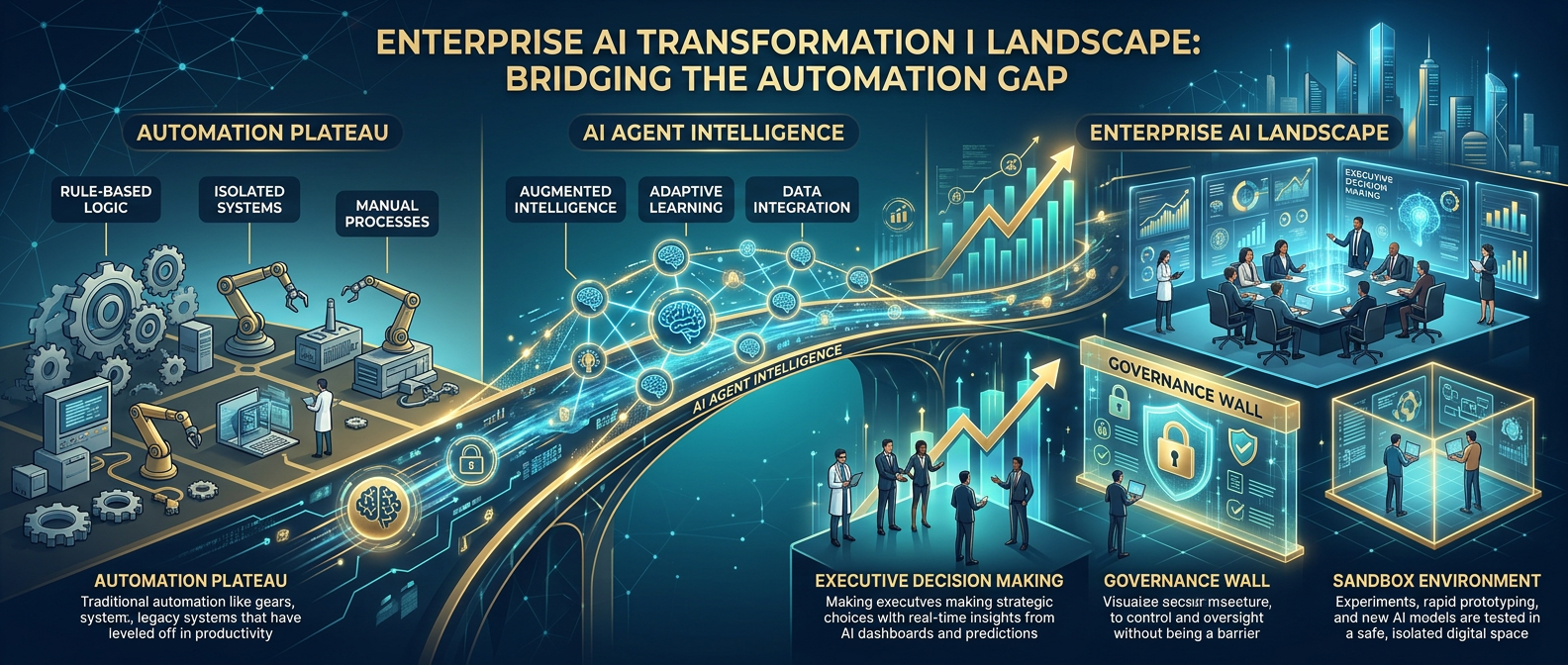
The Automation Plateau
Decades of automation investment have digitized the deterministic skeleton of enterprise operations. But what remains is precisely the hard stuff:
- 35% of finance professionals' time goes to high-value insight work — the other 65% is routine data collection and validation (NetSuite)
- McKinsey: 80% of time consumed by reporting and manual transactions
- Despite 98% of finance leaders investing in automation (McKinsey 2024 CFO Pulse), 41% of CFOs report fewer than a quarter of their processes are actually automated
Traditional automation hits a wall — it excels at deterministic sequences on structured data, but enterprise reality is probabilistic, exception-laden, and context-dependent.
The Gap of Judgement
The "Gap of Judgement" is the space between what rule-based automation can handle and what enterprise operations actually require:
- Left of the gap: If-then logic, structured data, predictable sequences (RPA/ERP territory)
- Right of the gap: Unstructured reasoning, exception handling, cross-system translation, inference under ambiguity
This isn't a complexity problem — it's a type problem. LLMs are the first technology that can operate in the inference space, handling ambiguity and multi-step reasoning. But raw capability isn't enough for enterprise deployment.
Three Stages of Agent Maturity
- Stage 1 — Chatbots & Copilots: AI answers questions; humans decide. Useful, but doesn't close the gap — human remains in the critical path
- Stage 2 — True Agents: Autonomously orchestrate multi-step processes, call APIs, read/write enterprise systems — this begins to close the Gap of Judgement
- Stage 3 — Enterprise Maturity: Three operational modes:
- Reactive: Discrete tasks, read-only, stateless
- Adaptive: Builds institutional knowledge via Bayesian confidence scoring
- Proactive: Bounded autonomy with live enterprise state representation
The Central Problem Is Control, Not Capability
The real challenge: deploying LLM capability within enterprise compliance, auditability, and regulatory boundaries.
"The productive relationship between these two things is not the LLM crashing through the wall. It is a deliberate architectural interface."
Evaluating enterprise AI primarily on capability benchmarks is misleading. The right question is: how well has the architecture been designed to make capability safely operable in this environment?
The Enterprise Sandbox
The architectural response: an execution boundary inside which agentic reasoning operates, insulated from direct production system access until outputs clear governance checks.
Key design principles:
- Enterprise systems (SAP, ServiceNow, Excel) connect via structured APIs
- Agentic processing happens inside the boundary
- Outputs exit through a safety mechanism layer before reaching human review queues or governed workflows
- Agents never touch live production databases directly
- Agents do not replace enterprise systems — they operate inside them
Simulation Before Action: The World Model
A technically significant idea: the Enterprise World Model — a live representation of enterprise state that agents reason against before committing actions to real systems.
Example: an agent proposes changing vendor payment terms → the world model reveals 47 open invoices, 12 pending POs, 3 blocked payments → constraint checks run → action approved or blocked before touching production.
This enables agents to reason about systemic, second- and third-order effects that humans often fail to trace completely.
Multi-Layer Governance
The governance stack addresses different risk classes:
- Pre-action simulation: Blocks constraint violations upstream (world model)
- Human approval gates: Structured review with full reasoning chain visible — not just recommendations, but the reasoning behind them
- Append-only audit trails: Timestamped, field-level before/after state for every action — satisfies regulatory requirements
This shifts the question from "do we trust AI?" (categorical) to building empirical infrastructure through which trust can be earned incrementally.
Phased Autonomy Progression
| Phase | Mode | What Happens |
| 1 | Shadow Mode | Agent runs parallel to humans, no write access — pure calibration |
| 2 | Assisted Mode | Agent surfaces recommendations; humans approve before action |
| 3 | Supervised Autonomy | High-confidence cases execute autonomously; exceptions to human queue |
| 4 | Full Autonomy | Governed sandbox execution; humans manage policy and audit, not transactions |
Key Takeaways
- The automation plateau is structural, not a failure of effort — traditional automation has reached its logical terminus
- The Gap of Judgement is the type-level distinction between deterministic rules and probabilistic inference — LLMs are the first tool that can operate there
- Control architecture, not model capability, is the real enterprise AI challenge
- Integration, not replacement: The agentic layer sits above the existing tech stack, treating ERP/workflow systems as the data substrate
- Phased progression from shadow mode to full autonomy provides the empirical evidence needed to justify each step of expanded trust
Infographics