LLM Watch Weekly: When Scale Isn't...

LLM Watch Weekly: When Scale Isn't Enough
Main Thesis
This edition challenges the prevailing assumption that scaling AI models — more data, bigger models — automatically solves capability gaps. Across multiple research papers, a clearer picture emerges: targeted interventions beat raw scale, evaluation benchmarks are finally catching up to real-world complexity, and the tension between specialisation and flexibility remains a central open problem.
Key Research Summaries
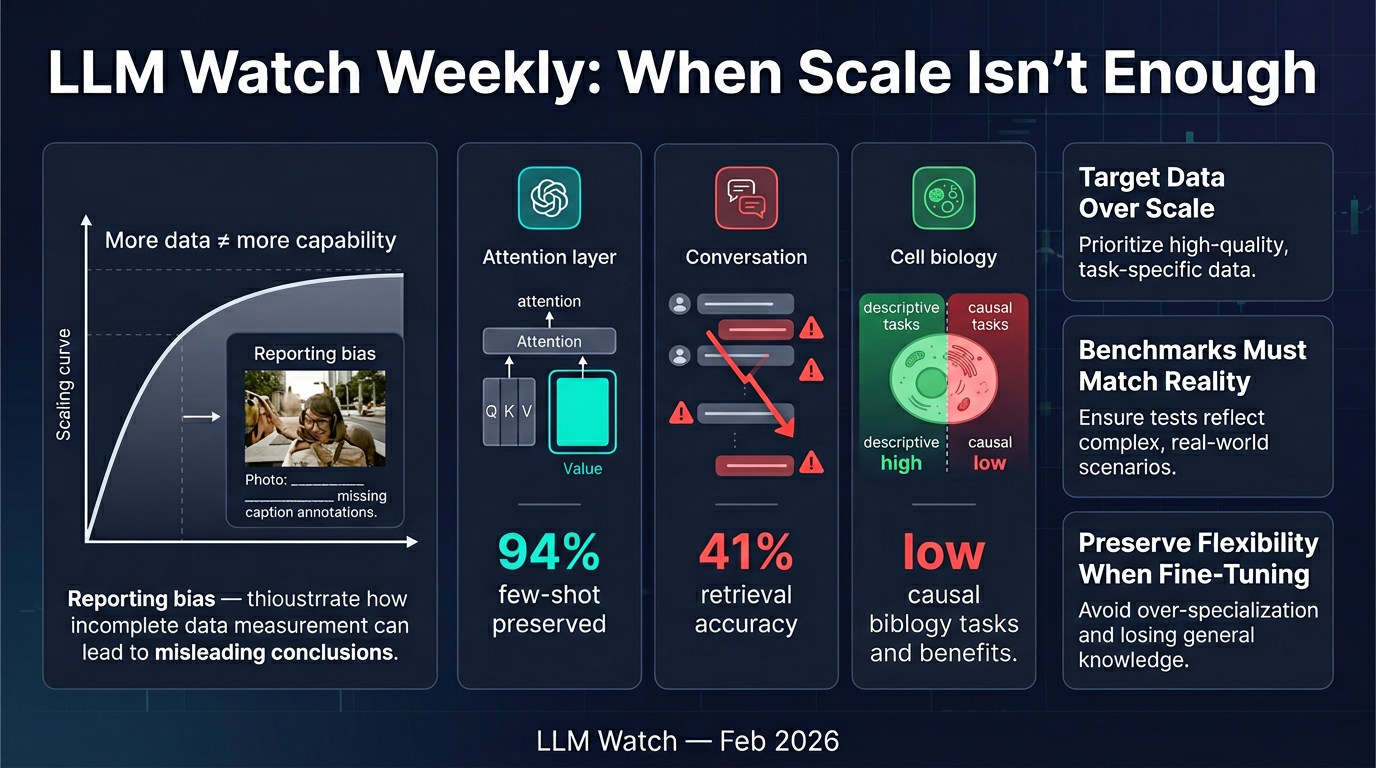
1. 📷 Vision-Language Models & Reporting Bias
Core finding: VLMs consistently fail at counting, spatial reasoning, negation, and temporal reasoning — not because of insufficient scale, but because human captions systematically omit this information (reporting bias). People caption photos to add context, not to describe what's visually obvious.
- Counting info appeared in fewer than 8% of captions across datasets
- Scaling data size, model size, or language diversity did not improve these specific capabilities
- Fix: Curating annotations that explicitly capture tacit information (counts, spatial relationships, temporal details) produced substantial improvement
- Even synthetically generated data inherited reporting bias from human-produced training text
2. 🔧 Fine-Tuning Without Losing In-Context Learning
Core finding: Fine-tuning all attention parameters degrades few-shot/in-context learning ability. But updating only the value matrix (freezing query and key projections) preserves in-context learning while still achieving zero-shot gains.
- Full fine-tuning reduced few-shot accuracy by 23–31%
- Value-matrix-only fine-tuning preserved 94% of original few-shot performance
- Theoretical explanation: Q/K projections govern where the model attends (in-context learning mechanism); V projections govern what is extracted (task-specific knowledge)
- Easy to implement in standard frameworks — no architectural changes required
3. 💬 Multi-Turn RAG Failures (MTRAG-UN Benchmark)
Core finding: Real conversational RAG fails badly on realistic edge cases that current single-turn benchmarks ignore.
- Models correctly identified unanswerable questions only 38% of the time (rest hallucinated)
- Retrieval accuracy on non-standalone questions: 41% vs. 73% on standalone questions
- Models asked for clarification on underspecified questions only 11% of the time
- By the 5th conversation turn, retrieval accuracy dropped 18 percentage points
- Benchmark (666 tasks, 2,800+ turns, 6 domains) is publicly available
4. 🔬 Single-Cell Biology Reasoning (SC-Arena)
Core finding: LLMs can describe cells reasonably well but fail at mechanistic/causal reasoning.
- Cell type annotation accuracy: ~78% for top models
- Perturbation prediction accuracy: only 34%
- Causal QA accuracy: below 30%
- Knowledge-augmented evaluation (using biological ontologies) achieved 0.89 correlation with expert biologists vs. 0.52 for string-matching
5. 📈 Time Series QA (PATRA)
Core finding: Explicitly extracting trend and seasonality components before language alignment outperforms end-to-end approaches, especially on complex reasoning.
- Trend identification: 91% vs. 84% for next-best
- Multi-step reasoning: 67% vs. 48% for baselines
- Balanced reward mechanism (weighting harder tasks more heavily in RL) prevented easy examples from crowding out complex reasoning development
Three Overarching Themes
| Theme | Insight |
| Limits of scale | Specific capability gaps require targeted data curation and architectural choices, not just more compute |
| Evaluation catching up | New benchmarks stress-test realistic, messy usage rather than clean single-turn averages |
| Specialisation vs. flexibility | Fine-tuning and domain adaptation trade general capability for task performance — this tension remains unsolved |
Practical Takeaways
- VLM apps requiring counting, spatial reasoning, or negation should expect failures regardless of model size — invest in targeted data collection
- Fine-tuning pipelines should freeze Q/K attention projections and update only value matrices to preserve few-shot flexibility
- RAG systems must explicitly handle unanswerable, underspecified, and non-standalone queries — don't assume single-turn benchmark scores reflect real usage
- Time series analytics tools benefit from classical decomposition (trend/seasonality extraction) as a preprocessing step before LLM reasoning
- Mixed-difficulty training should use balanced reward weighting to prevent easy examples from dominating gradient updates