I Tested Cowork, Lindy, Sauna, and Opal Against 3 Questions. The Best Scored 1 out of 4.

Summary: I Tested Cowork, Lindy, Sauna, and Opal Against 3 Questions. The Best Scored 1 out of 4.
Main Thesis
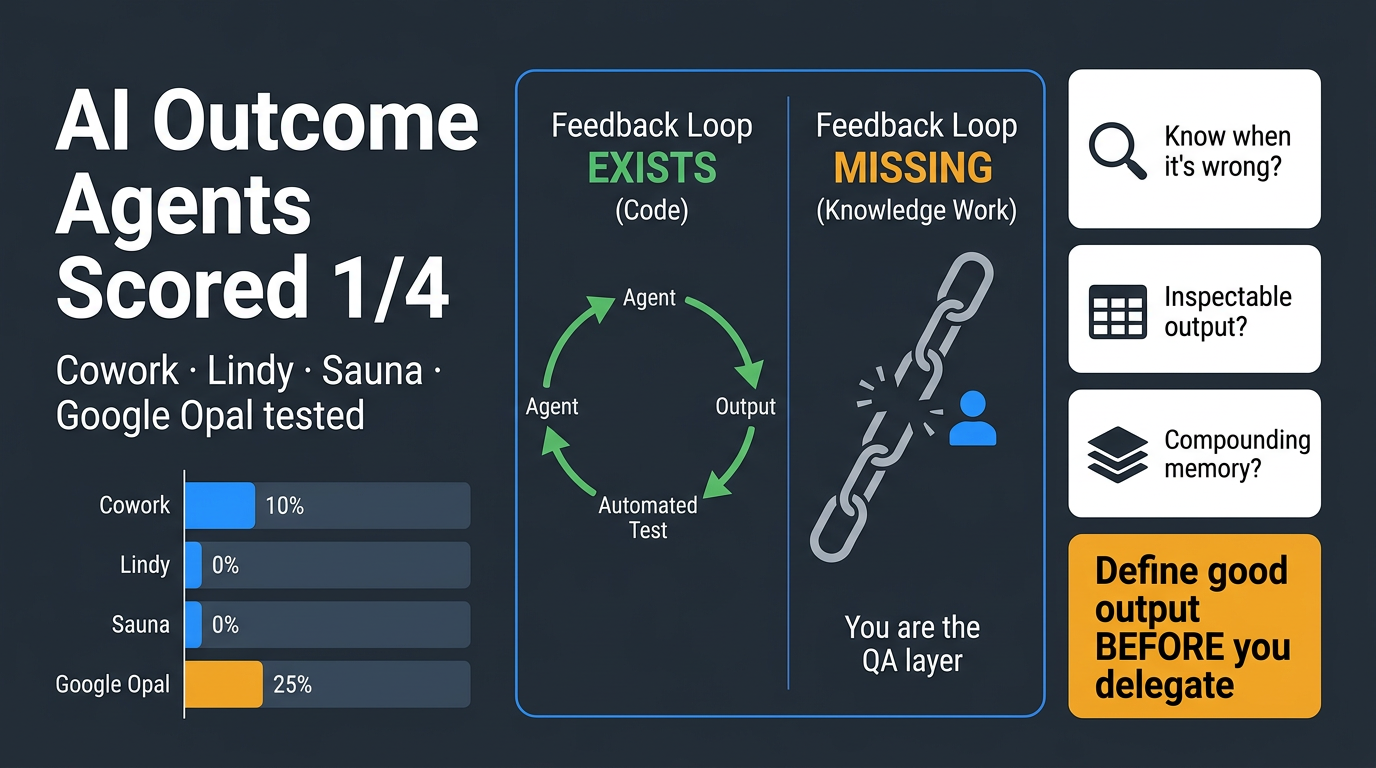
A wave of 'outcome agent' tools (Lindy, Sauna, Google Opal, Cowork, Obvious) are pitching software that does the work instead of helping you do the work — but almost none of them can answer the fundamental question: how does the agent know its own output is any good?
The core insight is a structural one: AI agents excel in environments with automated feedback loops (like coding, where tests pass or fail) but struggle in knowledge work environments (like drafting strategy memos) where the human is the only feedback mechanism.
Key Findings
- Best performer scored only 1 out of 4 on the evaluation framework — a damning result across the board
- The reason code-based AI agents succeeded first is structural: code has test suites that provide instant, objective feedback. Knowledge work has no equivalent
- Most outcome agent demos sidestep this problem entirely, hiding it behind polished UI and impressive-looking outputs
- Tools reviewed: Cowork, Lindy, Sauna (Obvious), and Google Opal — all tested against a 3-question framework
- A single AI agent (likely Manus or similar) triggered a quarter-trillion-dollar selloff in enterprise software stocks, despite being a research preview that stops working when your laptop sleeps
The Evaluation Framework (3 Questions)
Nate builds a framework around the feedback-loop insight to separate real agents from fake ones:
- Does the agent know when it's wrong? (automated vs. human-only feedback)
- Is the output inspectable? (can you audit what it did and why?)
- Does context compound over time? (memory architecture that improves with use)
Practical Takeaways
- Write the tests before the agent runs the work — define what 'good output' looks like before delegating
- Look for agents with inspectable surfaces — you need to see reasoning, not just results
- Memory architecture matters — agents that retain compounding context are structurally superior
- Use the included two-phase evaluation prompt to score any agent tool, then build a delegation spec calibrated to its actual weaknesses
- The pitch ('outcomes, not answers') might be right eventually — but the infrastructure to support it reliably doesn't yet exist at the level being marketed
Bottom Line
Outcome agents are being sold ahead of their actual capabilities. Until feedback loops in knowledge work are solved, humans remain the QA layer — and most tools aren't designed with that reality in mind.