GPUs Just Got 6x More Valuable. No New Hardware Required.
Updated
•2 min read
GPUs Just Got 6x More Valuable — Nate's Substack Summary
Main Thesis
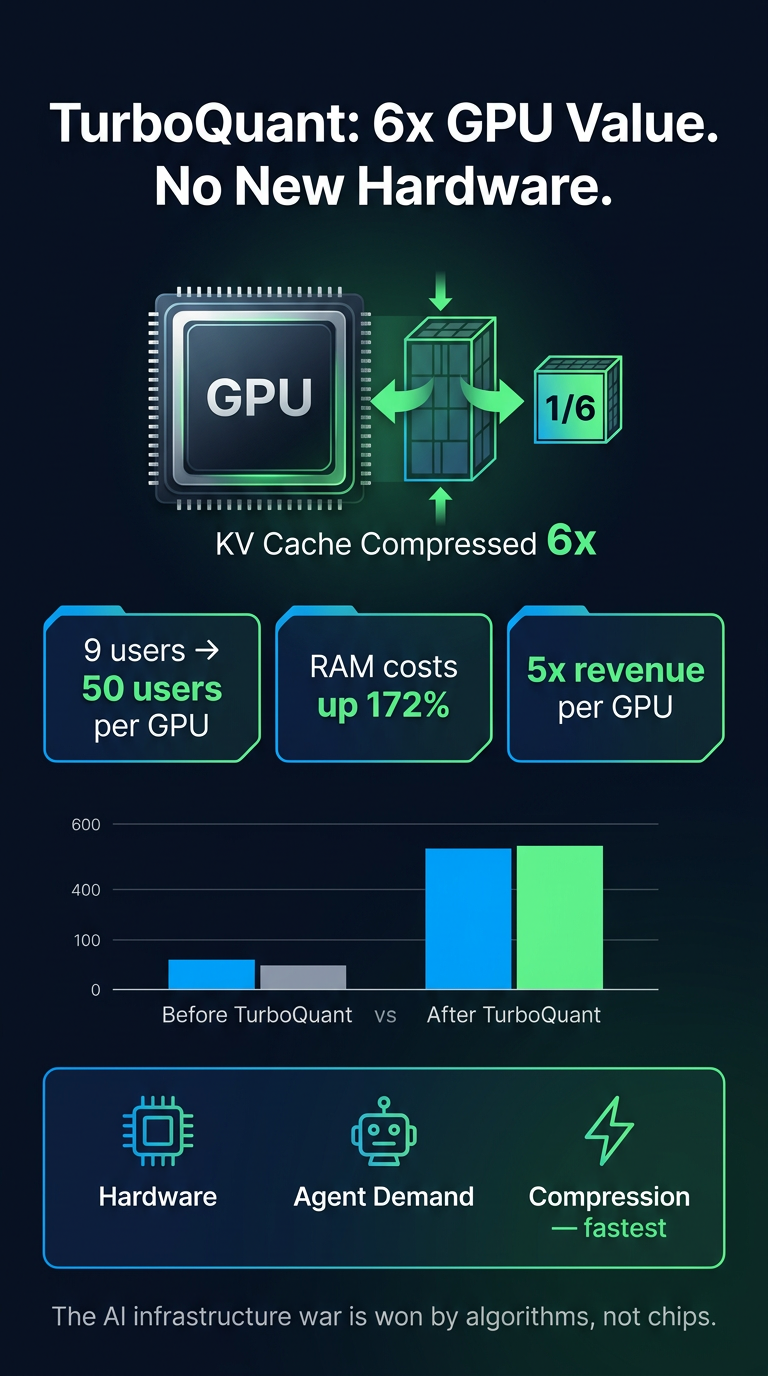
The real competitive advantage in the AI infrastructure war isn't faster chips or bigger fabs — it's a compression algorithm. A paper published by Google Research on March 25, 2026, called TurboQuant (nicknamed 'Pied Piper' by the internet) compresses the working memory (KV cache) that AI models use during inference by 6x, with zero accuracy loss and no retraining required.
Key Findings
- What TurboQuant does: Compresses the KV cache (the memory AI models use during every conversation) by 6x with no accuracy degradation. Drop-in compatible — no retraining or calibration needed.
- Concurrency leap: A GPU that previously served 9 concurrent users can now serve 50.
- Revenue impact: The 6x memory compression translates to approximately a 5x increase in revenue per GPU.
- Hardware cost context: Server RAM has risen 172% in 18 months, making existing fleet efficiency dramatically more valuable.
- User impact: Longer context windows and cheaper tokens are coming as a direct result.
- The KV cache = RAM insight: A startup has effectively demonstrated that the transformer architecture is a literal computer — making compression of its memory as strategically important as RAM compression in traditional computing.
Three Forces Framework (Paywalled Detail, Previewed)
- Constrained memory supply — GPU RAM is expensive and scarce.
- Exploding agent demand — AI agents require far more concurrent memory than single-turn chat.
- Compression as the third force — Operates on a faster timescale than hardware or demand cycles, giving it outsized leverage.
Why Compression Moves Fastest
Hardware improvements take years (fab cycles, chip design). Demand growth is continuous. But a compression algorithm can be deployed overnight across existing fleets — making it the fastest-moving variable in the stack.
Who Wins / Who Loses (Previewed)
- Winners: Google (published TurboQuant), enterprises running their own inference, developers facing high token costs.
- Losers: NVIDIA (less urgency to buy new GPUs), middleware layers that assumed hardware scarcity as a moat.
Practical Takeaways
- If you're running AI inference, watch TurboQuant adoption — it could dramatically cut your costs without new hardware.
- If you're investing in AI infrastructure, compression efficiency is now as important a metric as raw compute.
- Context windows are about to get much longer and much cheaper for end users.
- The moat in AI infrastructure is shifting from silicon to software-level efficiency.