Does Agents Actually Help Coding
Updated
•3 min read
Does AGENTS.md Actually Help Coding Agents?
Source: Elvis Saravia's AI Newsletter | Feb 26, 2026
Main Thesis
Developers widely assume that context files like AGENTS.md or CLAUDE.md meaningfully improve coding agent performance. A new study from ETH Zurich's SRI Lab rigorously tests this assumption — and the results are more nuanced than most practitioners expect.
Paper: Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?
The Study Setup
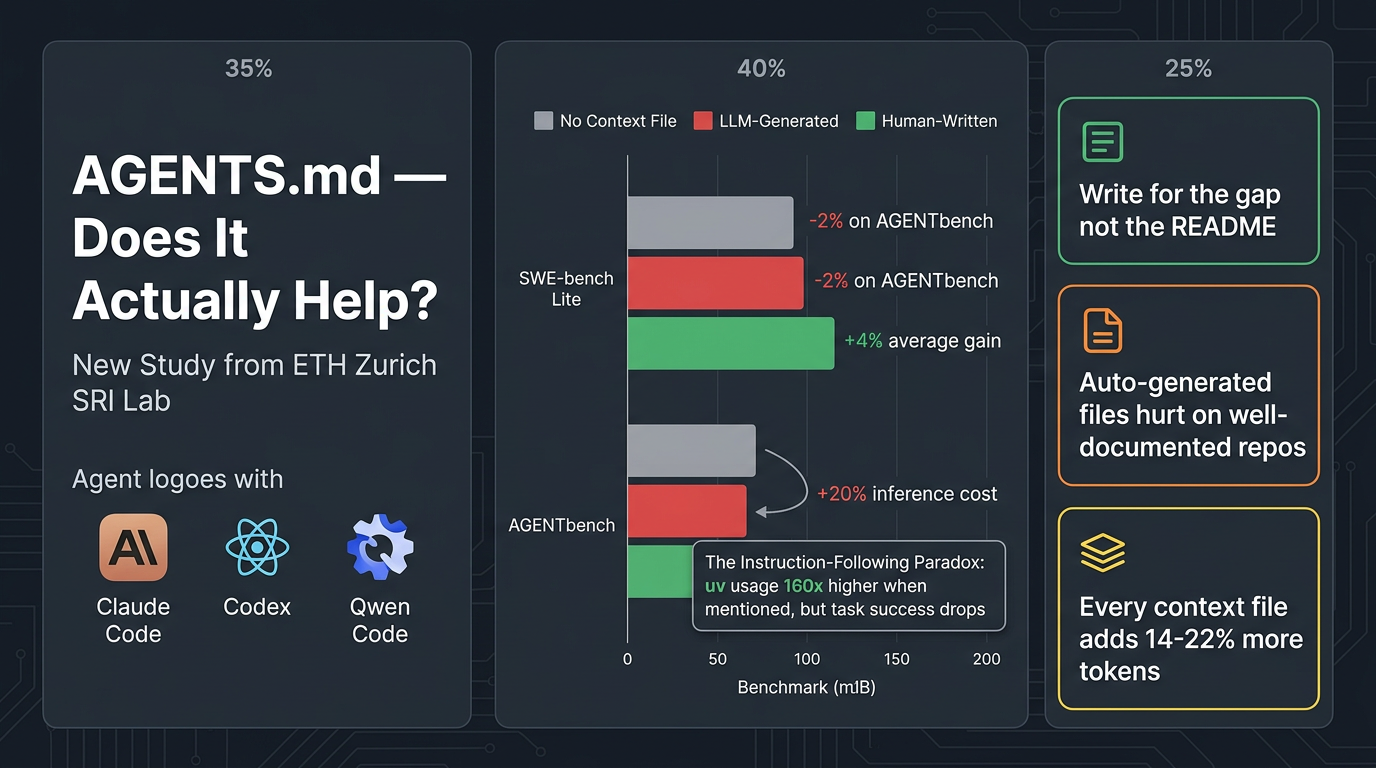
- Three agents tested: Claude Code (Sonnet-4.5), Codex (GPT-5.2 / GPT-5.1 mini), and Qwen Code (Qwen3-30b-coder)
- Benchmarks: SWE-bench Lite (standard) + AGENTbench (new benchmark introduced in the paper)
- AGENTbench: 138 instances from 12 less-popular Python repos, all with developer-written context files averaging 641 words across 9.7 sections
- Each agent ran tasks under three conditions: no context file, LLM-generated context file, human-written context file
Key Findings
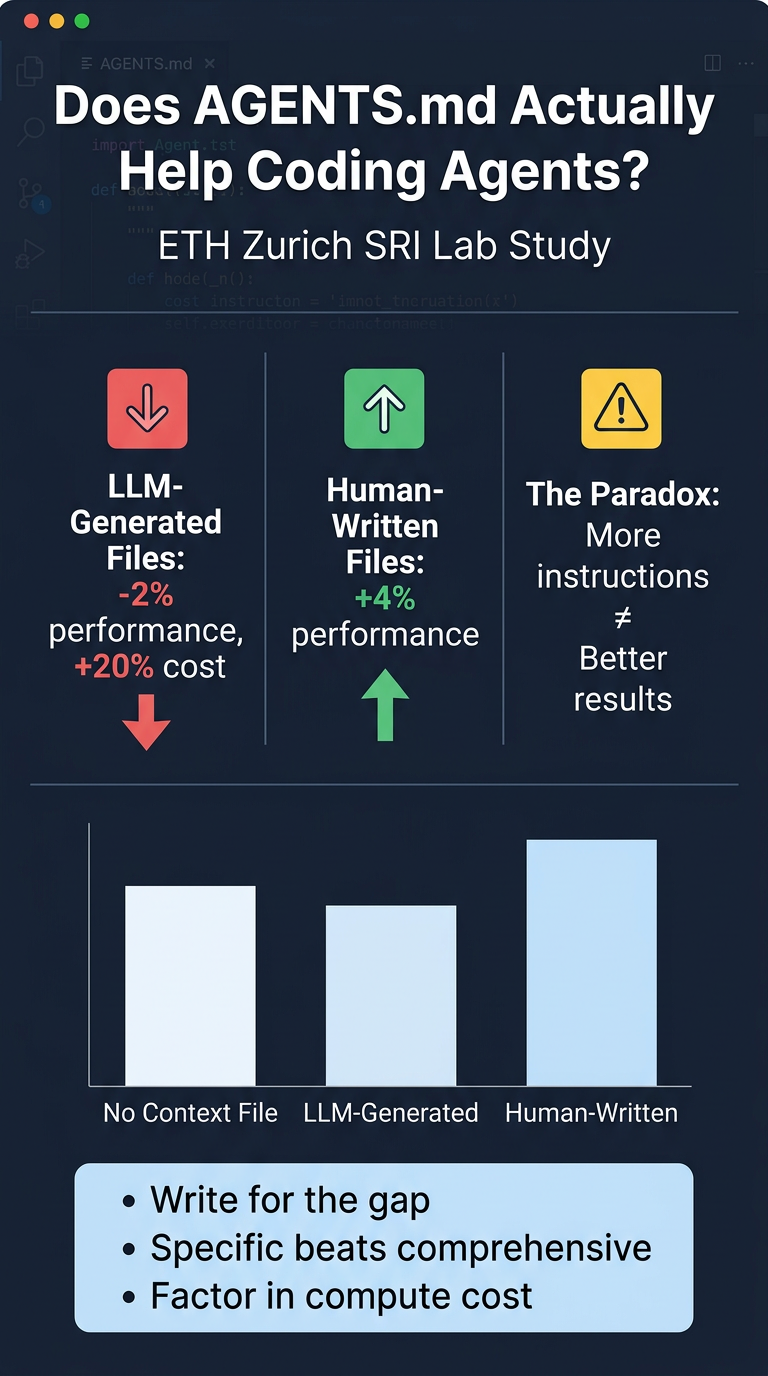
🔴 LLM-Generated Context Files Hurt Performance
- Drop task success by 0.5% on SWE-bench Lite and 2% on AGENTbench compared to no context file
- Increase inference cost by over 20%
- Root cause: LLM-generated files tend to restate information already in READMEs and docs — redundant content that adds noise, not signal
- When existing docs were removed before generation, LLM-generated files improved by 2.7% and outperformed human-written ones
🟢 Human-Written Context Files Help (On Their Turf)
- Produce a ~4% improvement over no context on average across both benchmarks
- Work because maintainers write them to capture non-obvious, additive information — specific tooling decisions, CI quirks, non-default conventions
⚠️ The Instruction-Following Paradox
- Agents follow context file instructions faithfully (e.g.,
uvusage jumped 160x when mentioned in a context file) - But following more instructions ≠ solving the problem faster or better
- Agents with context files run more tests, search more files, and generate more reasoning output — more activity, not better activity
- Detailed directory overviews (included in 100% of LLM-generated files) don't reduce steps to reach the relevant code
💰 The Cost Floor
- Every context file — human or auto-generated — adds 14–22% more reasoning tokens and 2–4 additional steps
- Instruction-following costs compute regardless of whether the instructions help
Practical Takeaways
- Write for the gap, not the overview — Context files should encode what the repo doesn't already explain. Avoid restating the README.
- Specific > comprehensive — Tool choices that diverge from defaults, non-obvious test configs, and non-apparent constraints are high-value. Codebase overviews are low-value.
- Auto-generated files need a rethink — A generator that explicitly avoids redundant content and extracts non-obvious conventions would perform significantly better.
- Factor in cost — For high-volume agentic pipelines, a 20% inference cost increase is material. The gains must justify the spend.
- Sparse-doc repos benefit most — Teams with unusual tooling or sparse documentation have the most to gain from context files. Well-documented popular repos may find them redundant by default.
Limitations
- Study limited to Python repositories only
- Only measures issue resolution — other benefits (consistency, security, convention adherence) aren't captured
- No longitudinal data — context file quality evolution over time is unstudied
Bottom Line
Context files are not magic, but they're not useless. Human-written files with specific, non-redundant information improve performance. Auto-generated files that reproduce existing documentation hurt performance. The quality of the outcome depends entirely on the quality of the instructions.
Resources: