AI Agents Weekly: Claude Code Review

AI Agents Weekly: Claude Code Review & More
From Elvis Saravia's AI Newsletter — March 14, 2026
Main Thesis
This issue covers a wave of practical AI agent tooling shipping in production, with a focus on multi-agent architectures for code quality, automated safety constraints, and expanding AI infrastructure ecosystems.
🔍 Top Story 1: Claude Code Review (Anthropic)
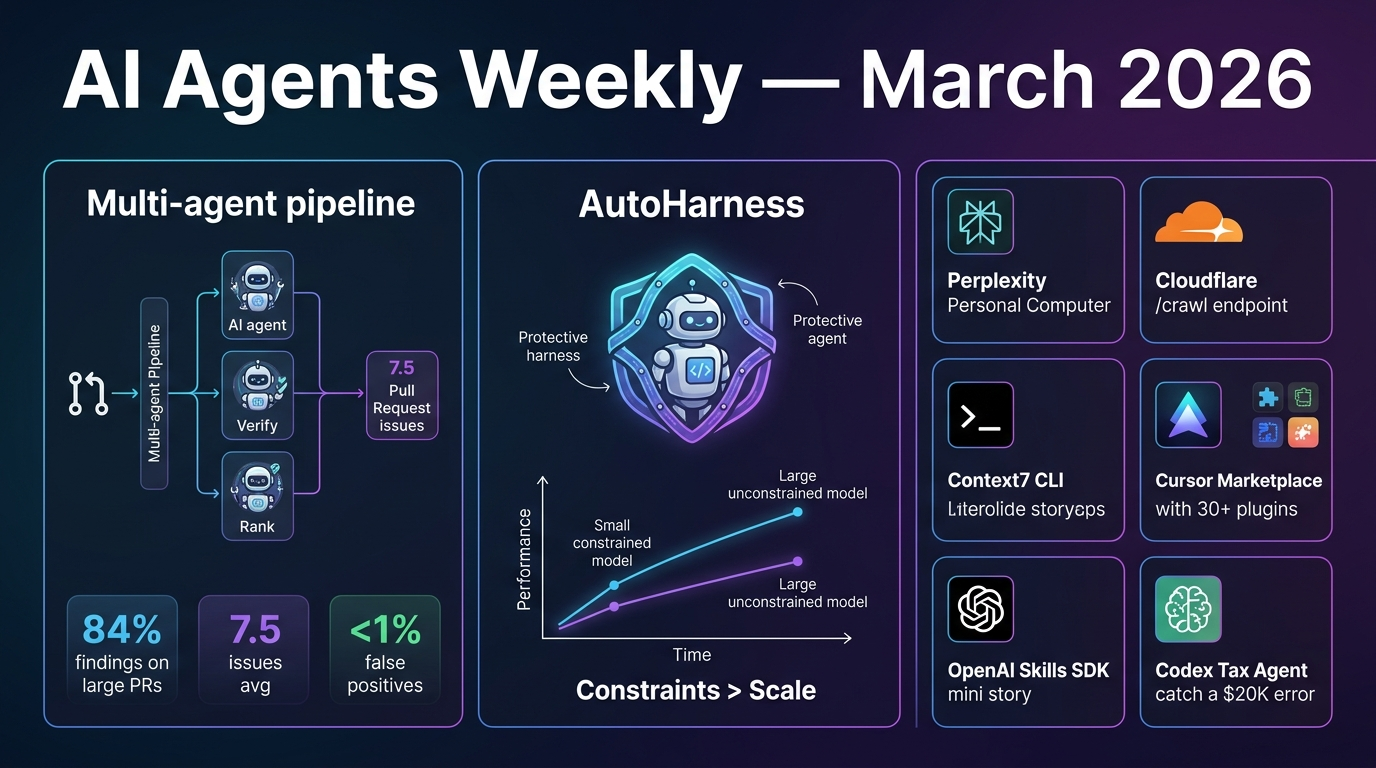
Anthropic launched Code Review for Claude Code — an automated multi-agent system that reviews every pull request by dispatching parallel AI agents to scan, verify, and prioritize issues.
How it works:
- Multiple agents run in parallel: one scans for issues, others verify findings to eliminate false positives, and a final pass ranks bugs by severity
- Outputs both a summary comment and inline code annotations
Key findings:
- Large PRs (1,000+ lines): findings 84% of the time, averaging 7.5 issues per PR
- Small PRs (<50 lines): findings 31% of the time
- <1% of flagged issues were marked incorrect by Anthropic engineers
- Caught production-critical bugs that appeared routine in diffs
Pricing & Access:
- Available as a research preview for Team and Enterprise customers
- Costs $15–25 per PR, billed on token usage
- Configurable monthly caps and per-repo controls
🔍 Top Story 2: AutoHarness — Automated Agent Constraint Synthesis
Researchers introduced AutoHarness, a technique enabling LLMs to automatically synthesize protective code harnesses around themselves — preventing illegal actions without human-written constraints.
Key findings:
- In a recent LLM chess competition, 78% of Gemini-2.5-Flash losses were due to illegal moves — AutoHarness eliminates this failure class entirely
- Tested across 145 different TextArena games
- Gemini-2.5-Flash + AutoHarness outperformed the larger Gemini-2.5-Pro (unconstrained), at lower cost
- Achieves zero-shot generalization: extends beyond games to full policy generation in code, removing runtime LLM decision-making entirely
- Outperforms GPT-5.2-High on certain benchmarks
Core insight: Rather than trusting a model to self-constrain, auto-generate a verified harness that makes illegal states unreachable — shifting safety from model behaviour to environment design.
📰 Other Headlines (Partially Paywalled)
| Story | Summary |
| Perplexity Personal Computer | Perplexity launches an always-on AI personal computer |
| Cloudflare /crawl | Single-call /crawl endpoint for web scraping in agents |
| Context7 CLI | Brings up-to-date library docs directly to any agent |
| Andrew Ng — Context Hub | New launch focused on context management for agents |
| Cursor Marketplace | Adds 30+ plugins for the AI code editor |
| OpenAI Skills for Agents SDK | New SDK capability for composable agent skills |
| Gemini Embedding 2 | Google launches next-gen embedding model |
| Meta MTIA Chips | Meta ships four MTIA AI chips in two years |
| Codex Tax Agent | Codex agent files taxes autonomously, catches a $20K error |
💡 Practical Takeaways
- Multi-agent parallelism beats single-pass review — Claude Code Review shows that splitting scan, verify, and rank into separate agents dramatically improves precision
- Constraints > Scale — AutoHarness proves that a well-constrained smaller model can outperform a larger unconstrained one, with cost savings
- Safety should live in the environment, not just in the model's behaviour — harness-based approaches are more reliable than prompt-level self-restraint
- AI infrastructure is maturing fast — from one-call crawl endpoints to plugin marketplaces, the tooling layer around agents is consolidating rapidly
📄 Papers
- AutoHarness: Automated Agent Constraint Synthesis — (arxiv link not publicly available in accessible content)