AI Agents of the Week: Papers You...
Updated
•2 min read
AI Agents of the Week – LLM Watch (March 1, 2026)
Main Thesis
This weekly roundup from LLM Watch surveys the most important recent research papers on AI agents, covering memory, planning, multi-agent coordination, safety, and evaluation frameworks.
Key Findings by Category
🧠 Memory & Continual Learning
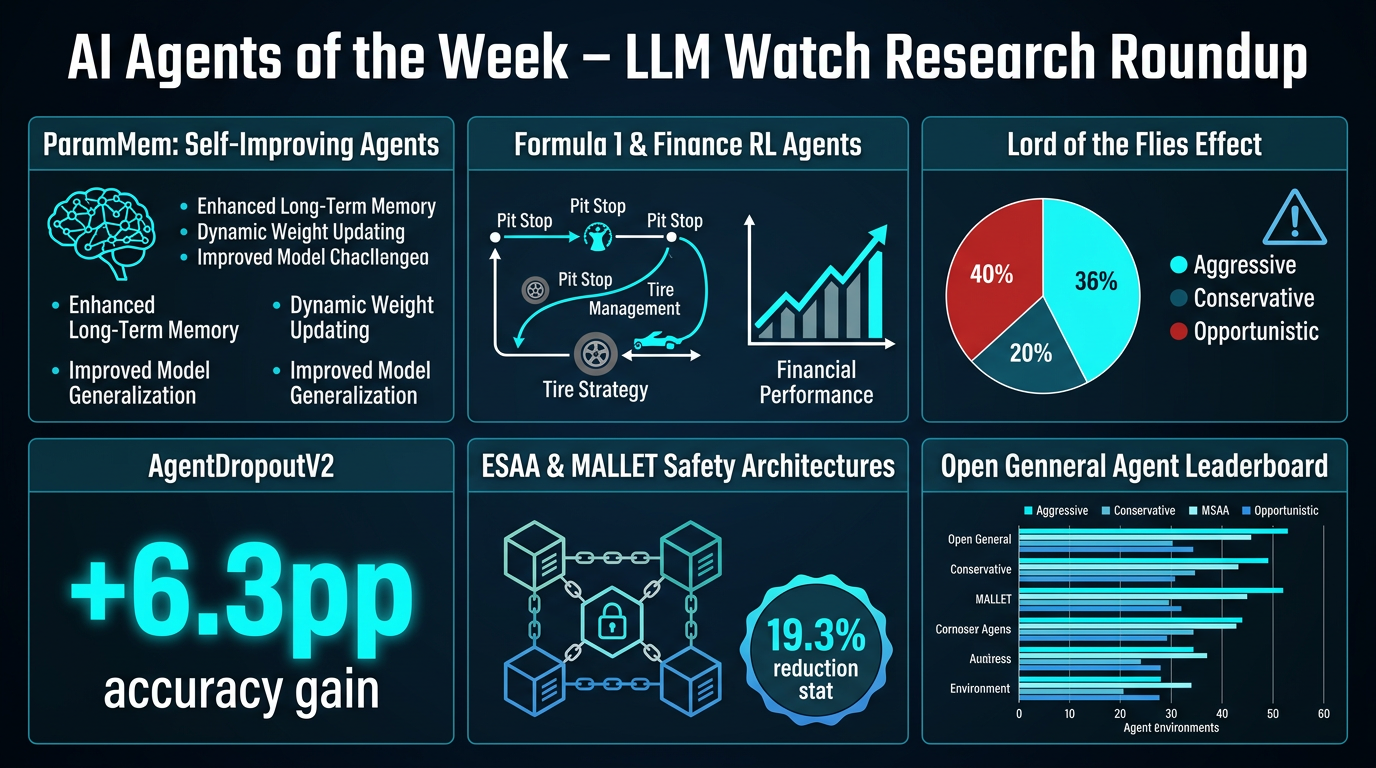
- ParamMem encodes cross-sample reflection patterns directly into model parameters, enabling agents to improve themselves via temperature-controlled sampling.
- Shows gains in code generation, math reasoning, and multi-hop QA.
- Enables weak-to-strong transfer across model scales — agents can self-improve without relying on stronger external models.
📋 Planning & Environment Interaction
- Formula 1 RL agents learn to balance tire wear, energy, aerodynamics, and pit-stop timing using self-play and pre-trained single-agent policies.
- "Toward Expert Investment Teams" shows fine-grained task decomposition significantly improves risk-adjusted returns in financial trading multi-agent systems.
- Key insight: competitive, multi-stakeholder environments demand both reactive adaptation and structured decomposition.
🤝 Multi-Agent Collaboration & Control
- "Three AI-agents walk into a bar" finds that when LLM agents compete for limited resources, three behavioral archetypes emerge: Aggressive (27.3%), Conservative (24.7%), and Opportunistic (48.1%).
- Counterintuitively, more capable agents increase systemic failure rates — dubbed the "Lord of the Flies" phenomenon.
- AgentDropoutV2 offers a remedy: a test-time pruning framework that intercepts and corrects erroneous agent outputs, achieving a +6.3 percentage point accuracy gain on math benchmarks.
🔒 Trust, Verification & Safety
- ESAA (Event Sourcing for Autonomous Agents) separates cognitive intention from state mutation using an append-only, cryptographically verified event log.
- Successfully orchestrated a clinical dashboard with 50 tasks, 86 events, and 4 concurrent LLMs (Claude Sonnet 4.6, Codex GPT-5, Gemini 3 Pro, Claude Opus 4.6).
- MALLET is a multi-agent emotional detoxification system reducing harmful stimulus scores by up to 19.3% while preserving semantic meaning.
🛠️ Tools & Frameworks
- General Agent Evaluation introduces a Unified Protocol and the Exgentic framework, producing the Open General Agent Leaderboard.
- Benchmarks 5 agent implementations across 6 environments, showing general agents can match domain-specific agents without environment-specific tuning.
Practical Takeaways
- Self-improvement without stronger models is becoming viable — ParamMem points toward truly autonomous agent iteration.
- Scaling agent intelligence ≠ better collective outcomes — coordination and safety mechanisms are essential as agents grow more capable.
- Architectural rigor matters — cryptographic event logging (ESAA) is a practical step toward auditable, trustworthy agent systems in high-stakes domains like healthcare.
- Evaluation standards are maturing — the Open General Agent Leaderboard fills a critical gap, making cross-architecture comparisons meaningful.
- Task decomposition granularity directly impacts performance — especially in financial and competitive multi-agent settings.